

100% call audit automation means scoring every call against your scorecard with AI, then routing a risk-weighted slice to human reviewers, instead of paying analysts to listen to recordings one at a time. A BPO running a 100% manual audit clause for an enterprise client cannot staff it past a few hundred agents without the QA team falling weeks behind, missing the SLA the audit was meant to protect. The fix is not more analysts. It is moving the listening-and-scoring work to automated scoring and keeping humans on calibration, disputes, and coaching.
If you run quality or WFM at a BPO, you have probably said some version of this out loud: "We are doing 100% call audits manually. The client requires it. But we only have three QA analysts for 400 agents." This piece walks the math on why that breaks, then lays out the three operating models teams use to get to full coverage.
What does a 100% manual call center qa audit actually cost in analyst hours?
Start with the arithmetic, because it settles the argument faster than any pitch.
Take 400 agents, each handling roughly 60 calls a day. That is about 24,000 calls per day across the program. In this call center QA model, a careful manual audit, listening, scoring against the form, logging the result, runs 8 to 12 minutes per call, whether you are checking automated scoring against human review or tracking key performance indicators, call center metrics, quality metrics, and first call resolution. Use 10.
24,000 calls at 10 minutes each is 240,000 minutes, or 4,000 analyst-hours, every day. An analyst gives you maybe 6 focused audit hours in a shift after breaks, calibration, and admin. So full coverage at this volume needs around 665 analysts. The team in the quote has three. Better QA coverage improves customer satisfaction and reduces complaints.
Three analysts at 6 hours and 10 minutes per call audit about 108 calls a day. Against 24,000, that is real coverage of under half a percent. The "100%" in the contract and the 100% on the floor are two different numbers, and the gap does not close by working weekends.
The cost shows up in three places. Headcount: full manual coverage at mid-size scale would cost more than the contract margin it protects. Consistency: when different analysts grade the same call, scores drift, the same call gets a different grade depending on who pulled it, and a sampled program amplifies that drift because each analyst owns a tiny, non-random slice. Timing: feedback that reaches an agent two or three weeks after the call rarely changes the behavior, so the audit produces a paper trail but not a quality lift.
Where is the SLA and customer satisfaction risk when audits fall behind?
The audit clause is usually tied to a service level. The client wrote "100% of calls reviewed for compliance" into the contract because they are themselves regulated, or because a past incident scared them. Those analyst-hour calculations affect call center metrics and other key performance indicators across call center operations. When your real coverage is a fraction of a percent, you are technically out of compliance with the term you signed, and the exposure is asymmetric.
A single missed mis-sold product, an unverified identity, a skipped disclosure, can trigger a penalty, a remediation project, or a QBR where you are explaining a breach instead of pitching expansion. The team in the quote has three. Quality metrics such as First Call Resolution (FCR) measure whether issues are resolved on first contact. The backlog itself is the risk. Calls you have not scored yet are calls where a problem is sitting undetected, accruing, until the client's own audit finds it before yours does.
The gap does not close by working weekends. Average Handling Time (AHT) tracks the duration of customer interactions and is another KPI affected by inefficient review processes. Manual call monitoring leaves too much room for delay, weak compliance adherence, and hidden compliance risks. Quality assurance metrics also help identify areas for improvement in service.
What are the three models BPOs use to move to automated call scoring?
There is no single right answer. When call monitoring falls behind, SLA risk sits in broader call center operations, so the model depends on client mix, contract terms, and how much human judgment a given program needs. Three patterns cover most of the field, and each shapes the quality assurance process, the qa process, and the quality management needed to keep reviews consistent and support continuous improvement. Monitoring for compliance is critical in highly regulated industries. Prioritizing security in QA tools is essential for compliance.
Model 1: Sampling plus AI triage
Keep a human-audited sample, but let AI score 100% first and decide what the humans look at as part of the broader QA process. Instead of a random 2%, analysts review the calls the system flags: low scores, compliance misses, high-emotion contacts, outliers. This kind of automated QA helps teams surface customer sentiment and spot customer frustration earlier. You keep human eyes on the riskiest interactions and stop spending them on clean calls.
Quality management encompasses both QA and QC processes, while quality control is reactive and addresses issues as they arise.
Good fit when a client will accept risk-weighted human review rather than a literal every-call human signature, and when you want the lightest change to existing QA rituals. Three patterns cover most of the field, including approaches that support continuous improvement and quality management across accounts. The weakness: you are still anchored to human throughput for the audited slice, so it scales better than pure manual but not infinitely. qa automation can also reduce reviewer effort without changing that core tradeoff.
Model 2: Full AI scoring with human calibration
AI scores every call against the scorecard as a form of automated QA, with humans moving off listening entirely and onto three jobs: calibrating the system so its scores match expert judgment, handling disputes, and running the edge cases. This is the model that actually delivers literal 100% coverage, because no interaction depends on an analyst having time. In practice, strong center quality assurance software also helps surface customer sentiment and moments of customer frustration when it prioritizes calls for human review.
Good fit when the client's "100% audit" requirement means 100% evaluated and evidenced, which is what most compliance clauses really need. The requirement to make it defensible: every automated score has to link to the transcript moment that justifies it, or you have swapped a slow audit for a black box the client won't trust. You keep human eyes on the riskiest interactions, which is where a mature center quality assurance approach and clear center quality assurance metrics matter most. Comprehensive monitoring can improve customer satisfaction in call centers. That structure also makes this model easier to run as a QA program instead of a one-off scoring exercise. With proper calibration, automated QA can achieve accuracy levels above 90%.
Model 3: Hybrid by client tier
Most BPOs do not run one model across the book. Tier your portfolio. Top enterprise accounts with strict regulatory clauses should sit inside a structured QA program that uses full AI scoring with human calibration, with quality assurance analysts and qa teams reviewing exceptions while center managers and call center managers keep governance aligned. Mid-tier accounts get sampling plus AI triage. Smaller or lower-risk programs stay on a leaner sampled review. You match audit intensity to contract value and risk, and you protect margin on the accounts that have the least of it.
Good fit for a mixed enterprise book, which is most of the market. This is center quality assurance supported by center quality assurance software. The cost is operational: you are running more than one process, so your QA platform has to support different scorecards and coverage rules per client without standing up a separate workflow each time. Even with literal 100% coverage, calibration still matters. A successful call center quality assurance program ensures consistent customer experiences. Call center QA software includes seven types for monitoring, so choose the mix that fits your audit needs. That flexibility is what makes the model defensible, along with clear center quality assurance metrics.
How does automated scoring feed back into agent performance and coaching?
Scoring is only half the value. The point of auditing every call is to change what happens on the next one, and call center managers or center managers usually make these tiering decisions with input from QA teams. Automated scoring closes that loop faster than manual QA can, because the results land while the call is still recent. Here is the cycle:
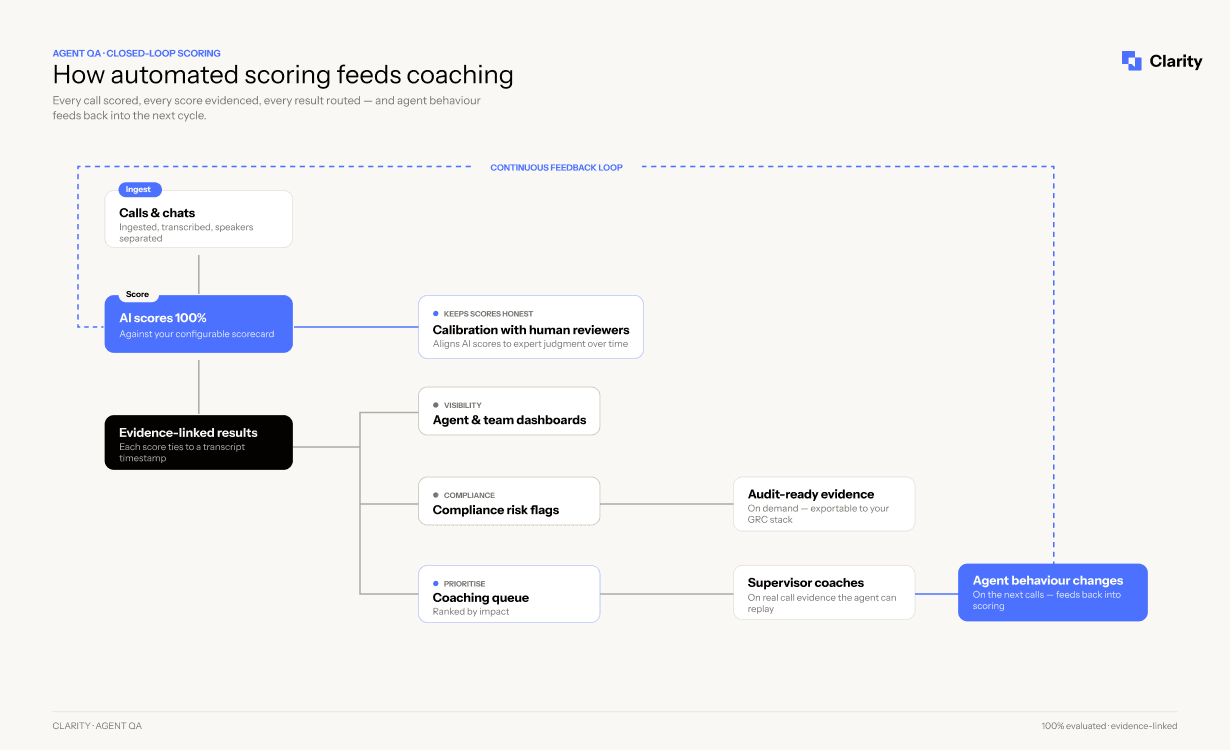
The loop matters because each stage removes a delay that kills manual QA. Scoring is immediate instead of weeks late. Coaching is ranked by impact instead of by whichever calls an analyst happened to pull. That helps with evaluating agent-customer interactions in a way that improves agent performance over time. It also gives supervisors a clearer view of communication quality, not just whether a script was followed. In stricter regulatory clauses and higher account tiers, quality assurance analysts can support oversight across models while supervisors use the results for agent development. And because every score points to the exact moment in the transcript, a supervisor coaches against evidence the agent can see, uses constructive feedback to guide self-assessment, and a disputed score gets resolved by replaying the call, not by arguing about it. Customer feedback can also be layered in to validate what the scorecard may miss after the interaction ends. Dedicated QA management ensures thorough and effective quality assurance processes.
How Clarity Agent QA runs full-coverage scoring
Clarity Agent QA automatically evaluates 100% of calls and chats against your scorecards instead of a 1 to 2% manual sample, giving teams full-coverage scoring that supports agent development as well as faster coaching. It applies the same rubric to every interaction, scores in Arabic and English including dialect and code-switching, and links every score to the transcript moment that justifies it, so results are explainable and disputes resolve against evidence rather than opinion.
Clarity reports 100% of conversations evaluated, roughly 20x the coverage of manual QA, around 70% lower QA operations cost, and scores delivered in under 5 minutes from call end. That last number is the one that changes coaching, because feedback lands while the call is still recent instead of weeks later. The point of auditing every call is to change what happens on the next one. Ongoing coaching and training are vital for agent development.
For a BPO, the product maps directly onto the three models above. Configurable scorecards ingest your existing evaluation matrix and weightings, so you can run different coverage rules per account without rebuilding the workflow. Evidence on every criterion is timestamp-anchored and exportable to your existing GRC stack, which is the audit trail an enterprise client's compliance clause actually asks for. And because every score points to the exact moment in the transcript, managers can give constructive feedback tied to evidence instead of opinion. And calibration keeps the automated scores aligned with your human reviewers over time, so the system earns trust instead of demanding it. For regulated GCC accounts, in-region processing options and PDPL controls keep the data where the contract requires. In call center quality assurance, that supports stronger service quality across contact center operations. QA reviews should evaluate both communication quality and procedural adherence. Combining internal QA scores with customer feedback improves assessment accuracy and helps track customer satisfaction. Built-in performance analytics also make contact center quality assurance easier to manage through clearer quality assurance reporting and better customer experience outcomes, while improving operational efficiency.
See how Agent QA scores every interaction at onclarity.com/agent-qa, or book a demo to run your own scorecard against a sample of live calls. Gamified performance management systems can enhance agent motivation and engagement while improving agent performance.
FAQ
Can AI really audit 100% of calls, or is it still a sample? It supports contact center quality assurance as well as call scoring, and it scores 100% of ingested calls and chats, not a sample. Humans move from listening to calibrating the system, handling disputes, and coaching.
Does automated scoring replace our QA analysts? No. It scales coverage to every interaction and frees analysts from manual listening. They calibrate scoring, work edge cases, and run coaching, which is where their judgment actually pays off and why is qa so important for continuous improvement. That broader coverage supports service quality and operational efficiency. Customer Satisfaction (CSAT) assesses customer experience and satisfaction levels. Average Handling Time (AHT) tracks the duration of customer interactions and can be reviewed alongside quality scores in performance analytics.
Will an enterprise client accept AI scoring against a 100% manual audit clause? Most clauses require 100% evaluated and evidenced, not 100% signed by a human. Evidence-linked, defensible scoring across every call typically satisfies that requirement, and gives the client better coverage than a manual sample ever did.
Can agents see why they were scored a certain way? Yes. Every score links to the transcript moment behind it, so supervisors coach against evidence and disputes are resolved by replaying the call. That helps teams deliver consistent customer experiences, strengthen customer loyalty, and track Net Promoter Score as a long-term signal.
Does it handle Arabic calls? Yes. It evaluates Arabic and English interactions, including dialect and code-switching, which matters for GCC delivery centers and day-to-day contact center operations.
How do we keep AI scores aligned with our standards? Through calibration. For a BPO, the product maps directly to QA workflows already in place, including quality assurance reporting across different accounts and workflows. Balancing quantitative and qualitative data is important in QA evaluations. The visibility from these reports also helps identify training needs for agents. Your human reviewers grade a set of calls, the system aligns to their judgment, and you tune the scorecard over time so automated scores match what your best evaluators would give.

